字符编码
参考链接
概念
字符集:为每一个字符分配一个唯一的码位,即字符和码位进行映射。
编码:将码位转换为计算机实际存储二进制数值的规则。在Unicode之前,编码都是直接存储字符集的二进制码位。
单位换算:1字节(byte) = 8位(bit) = 1111 1111 = FF = 255。
编码类型
ASCII
单字节,对数字,字母,标点符号,控制字符编码成 0~127
0000 0000 ~ 0111 1111
ISO-8859-1(Latin-1)
扩充 ASCLL 编码,对 ASCLL 单字节剩余的 128 位数编码进了西欧字符
0000 0000 ~ 1111 1111
GB2312,GBK,GB18030
扩充ASCLL编码,增加为2个字节,编码进中文字符
GB18030 > GBK > GB2312
Unicode(UCS)
Unicode 字符集:
使用3个字节,涵盖世界上所有字符,其中:
- 00 00 00 ~ 00 FF FF 基本平面(BMP)包含大部分常见字符
- 01 00 00 ~ 10 FF FF 增补平面包含其他字符
分成17个平面,每个平面可包含65536个字符。基本平面为第0平面,增补平面为第1~16平面。
因为 Unicode 字符集比较大,单个字符需要占用 3 个字节,直接保存码位需要占用太多内存,同时也不利于网络传输,因此需要进行编码,以此来压缩存储的大小。
UTF:UCS Transfer Format,指对 Unicode 字符集进行编码。
UTF-8 编码:
可变长编码,1~4字节
单字节的字符,字节的第一位设为0,和 ASCII 码完全相同
n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,
后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足
UTF-16 编码:
基本平面固定2字节,增补平面固定4字节
U+D800 ~ U+DFFF不属于任何字符,4字节时通过使用这个来区分
UTF-32 编码:
所有字符固定4字节
00 00 00 00 ~ 00 10 FF FF
UCS-2 编码:
只包含基本平面的2个字节,即在基本平面的编码,和UTF-16相同
UCS-4 编码:
所有字符固定4字节
00 00 00 00 ~ 7F FF FF FF,是 UTF-32 的父级
实际范围不超过 00 10 FF FF,跟 UTF-32 相同
BOM:
Byte Order Mark,字节顺序标记,在字节头加上指定特殊字节做标记
Big Endian:
字符0xABCD,BOM = FE FF,表示存储顺序为AB,CD。
Little Endian:
字符0xABCD,BOM = FF FE,表示存储顺序为CD,AB。
UTF-8-BOM:
BOM = EF BB BF,表明该编码是 UTF-8,
标准形式 UTF-8 是不加 BOM 的,因为 UTF-8 不需要表明字节顺序
加 BOM 容易在 windows 外的系统产生异常
ANSI:
在 windows 区域格式为【中文(简体,中国)】的设置下,ANSI = GBK
在cmd中,执行chcp 可看到“活动代码页:936”,963 即表示 GBK
编码实践
Notepad++ 的编码,可直接转换文件当前的编码方式
安装 Notepad++ 的 HEX-Editor 插件,可查看文件十六进制码
VsCode 的设置-文本编辑器-文件-编码,可设置使用哪种编码方式查看和编辑文件
Nginx中配置 charset utf-8; 可设置响应标头 Content-Type: text/html; charset=utf-8,浏览器根据响应标头中指定编码对响应实体进行解码
Base64
原理
base64 不属于字符编码,而是一种二进制编码,将二进制数据以字符串的形式展示或保存。
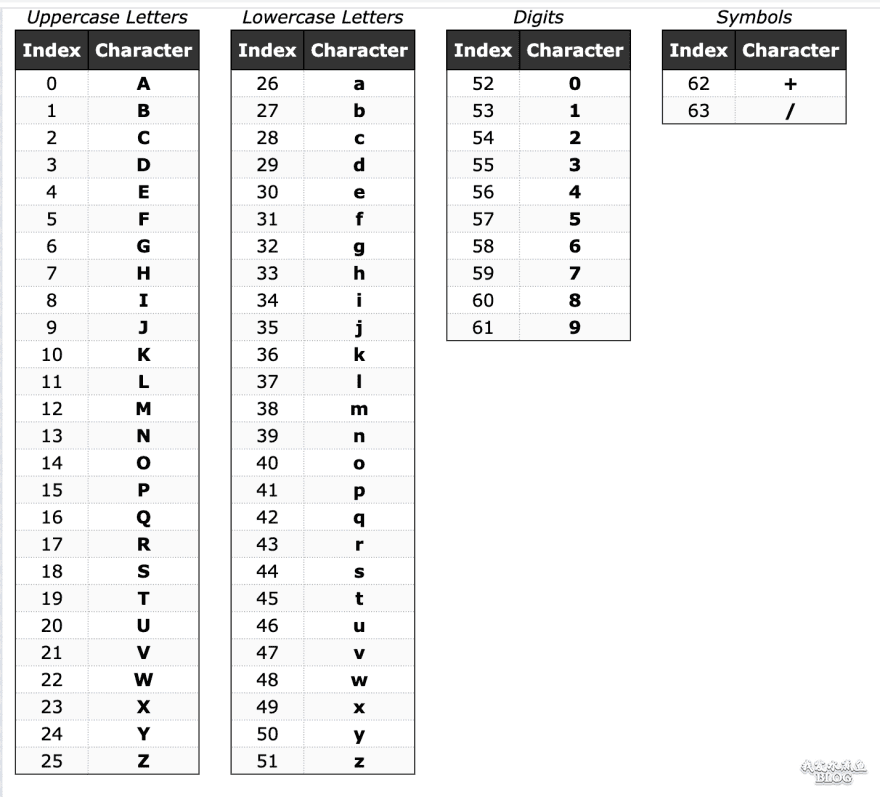
二进制中每 3个字节组成的 24 位,会重新分成 4 个 6 位,每 6 位由 1 个字符表示。2^6 = 64,即需要 64 个字符,由 [ a ... z A ... Z 0...9 + / ] 提供。
结尾 =
由于 base64 中是以 3 个字节转 4 个字符为一组,当结尾字节不足 3 个时,生成的字符也不足 4 个,此时补 = 至 4 个。
比如 "1",对应码位 "49",转 8 位二进制 "00110001",再按 6 位一组划分,"001100 100000" (下划线表示补 0),此时只能转成 2 个 6 位,转十进制后为 12 16,对应 base64 编码中的 “MQ”,还差的 2 个 6 位则用 2 个 “=” 表示。最终 "1" 转成 "MQ=="。
当结尾是 1 个字节时,差 2 个 6 位,补 2 个 = 。当结尾是 2 个字节时,差 1 个 6 位,补 1 个 = 。故 base64 的结尾会存在 0、1、2 个 = 。
// 字符串转base64,返回 MQ==
btoa("1");
// base64转字符串,返回 1
atob("MQ==");
URL安全
在标准 base64 中会出现 + / =,在 URL 中会造成歧义,处理方式:
- + 转 -
- / 转 _
- = 删除(base64 长度是 4 的整数倍,后续依据这个加回来)
let urlSafeStr = str.replace(/\+/g, "-").replace(/\//g, "_").replace(/=+$/, "");